Dendritic Learning
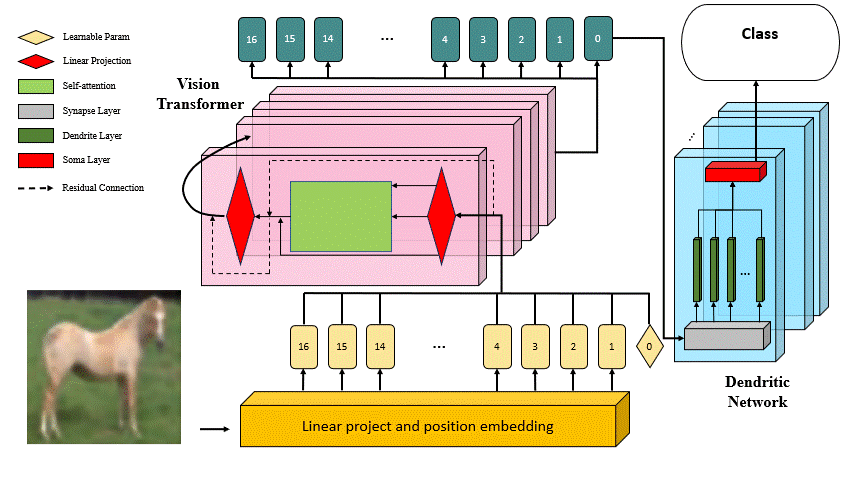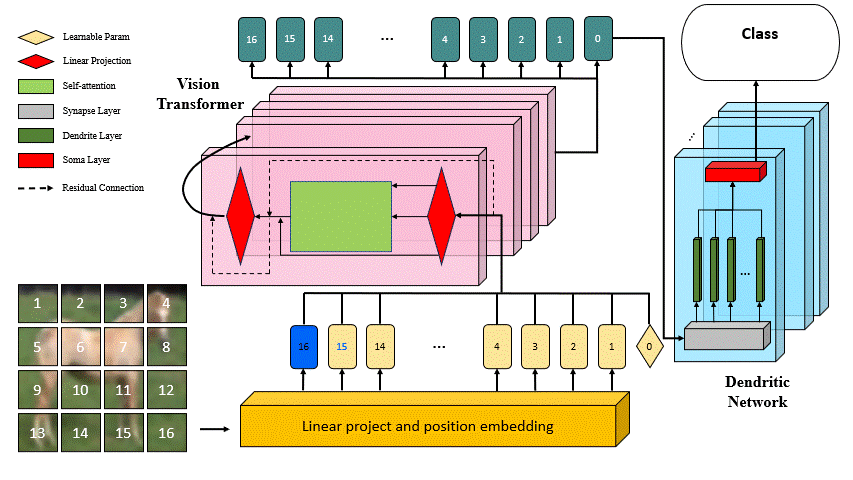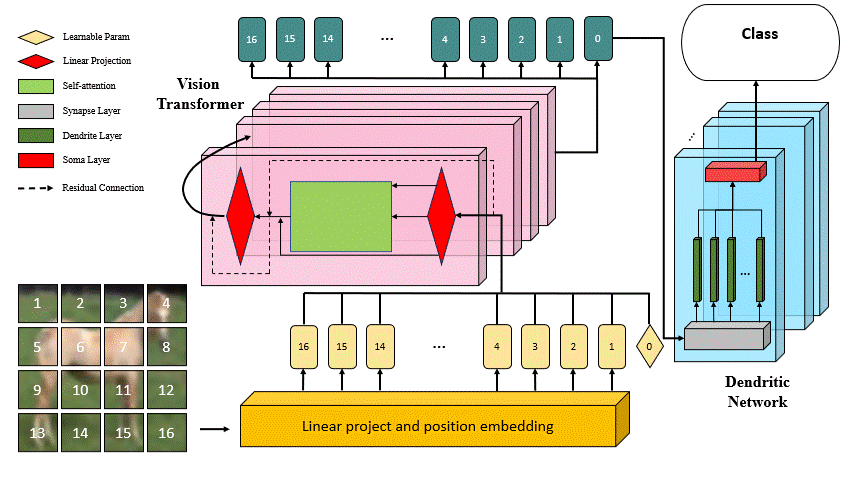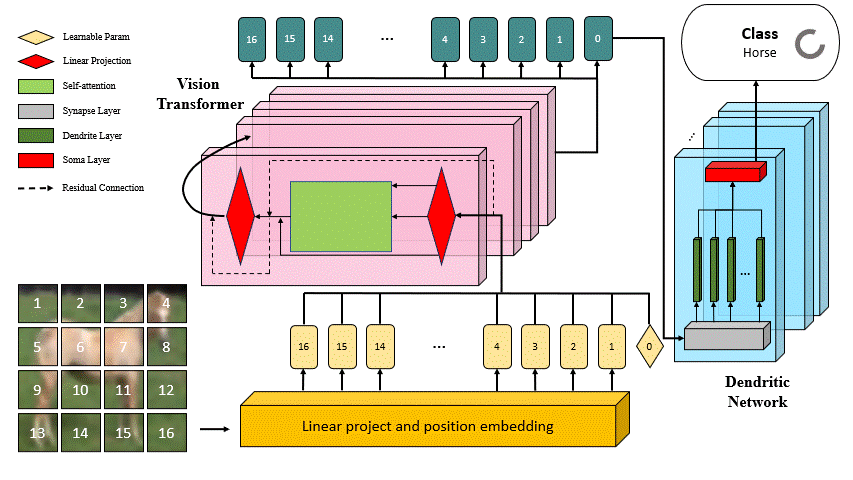
DVT: Dendritic Learning-incorporated Vision Transformer for Image Recognition
DVT is an innovative study introducing a Dendritic Learning-incorporated Vision Transformer, specifically designed for universal image recognition tasks inspired by dendritic neurons in neuroscience. The model's architecture incorporates highly biologically interpretable dendritic learning techniques, enabling DVT to excel in handling complex nonlinear classification problems.
The motivation behind DVT stems from the hypothesis that networks with high biological interpretability in architecture also exhibit superior performance in image recognition tasks. Our experimental results, as outlined in the associated paper, highlight the substantial improvement achieved by DVT compared to the current state-of-the-art methods on four general datasets.
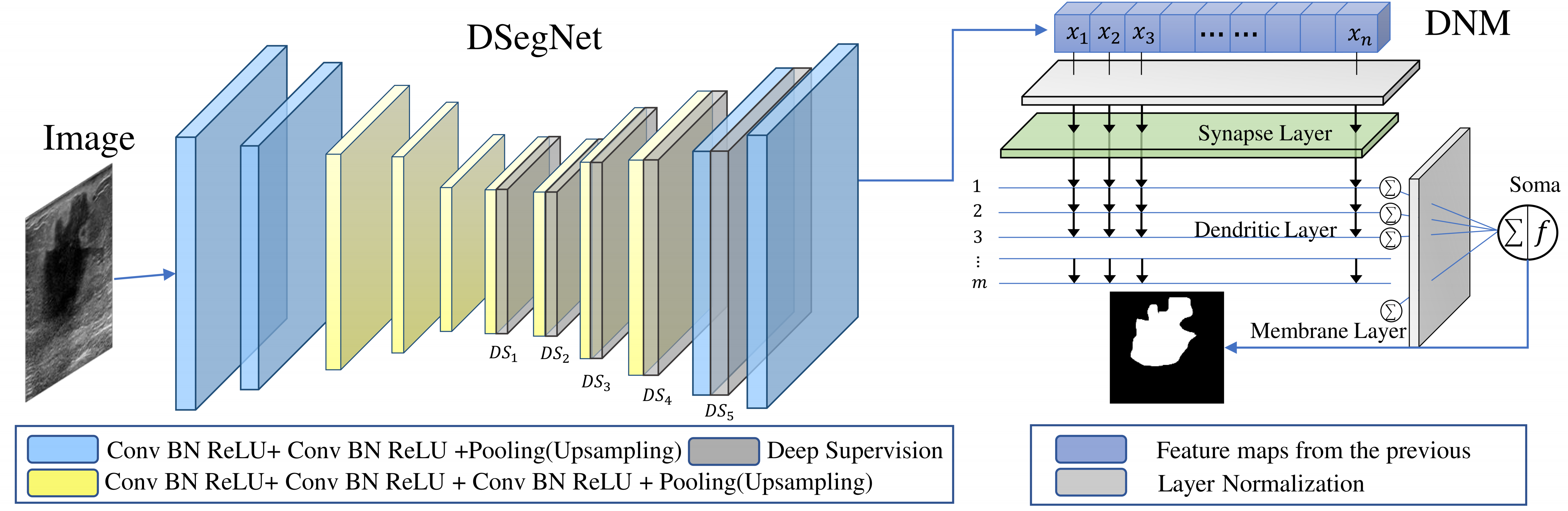
DDNet: Dendritic Deep Learning for Medical Segmentation
DDNet is a novel network that integrates biologically interpretable dendritic neurons and employs deep supervision during training to enhance the model's efficacy. To evaluate the effectiveness of the proposed methodology, comparative trials were conducted on datasets STU, Polyp, and DatasetB. The experiments demonstrate the superiority of the proposed approach.